i5 / P55 Lab Update - Now with more numbers
by Gary Key on September 15, 2009 12:05 AM EST- Posted in
- Motherboards
Applications-
Cinema 4D R11 x64
Cinema 4D R11 is one of our favorite programs to create high-end 3D images and animations. This particular program is sensitive to memory bandwidth and is well threaded. We track the time it takes to render a swimming pool layout.
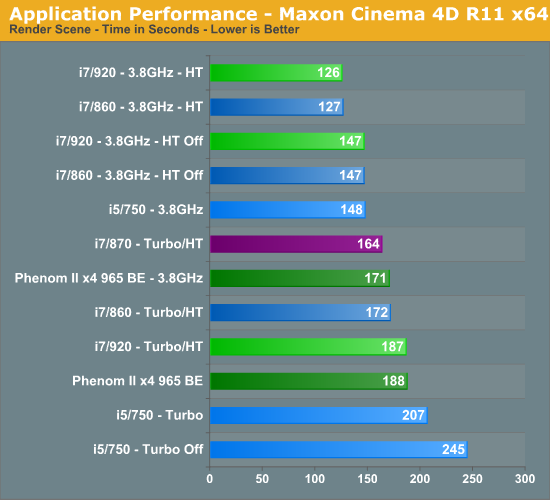
Our i7/920 finishes first with the i7/860 just a second behind at 3.8GHz and with HT enabled. Disabling HT decreases performance 15% when these two CPUs are overclocked. The 965 BE is 27% slower at 3.8GHz than the i7/920 with HT enabled and 14% with HT disabled.
Turbo mode benefits the i5/750 greatly in this benchmark as turning it off results in the 750 being 16% slower. However, pure CPU speed allows the 965 BE to finish the benchmark about 10% quicker than the 750 with Turbo enabled and 23% with Turbo disabled with a 28% higher base clock speed. Of course, the 965 BE is 17% more expensive based on CPU cost comparisons.
LightWave 3D 9.6 x64
Another popular 3D rendering program is Lightwave 3D 9.6. In this test we time the rendering of a single frame from an office building animation. The time to render the full scene is approximately four and a half hours. This title is also well threaded and sensitive to both memory bandwidth and latency.
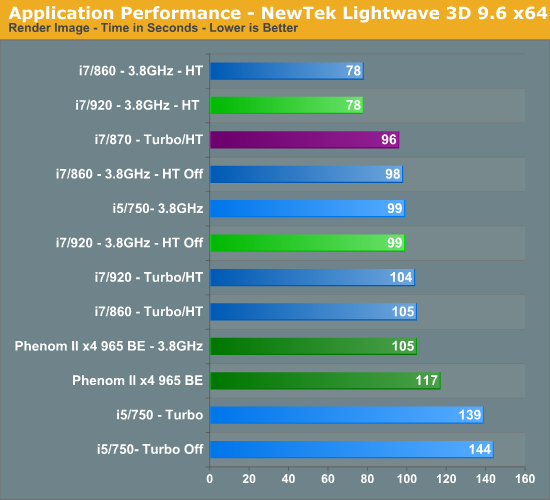
Lightwave also favors HT enabled processors with the 860/920 tying for first at 3.8GHz. Interestingly enough, Turbo mode on the i5/750 only offered a 3% improvement in this bench. The 965 BE scales very well as a 11% core speed increase nets a 10% improvement in the benchmark. However, the 965 BE still trails the 860/920 CPUs by 26% at 3.8GHz.
MainConcept Reference 1.61
One of our favorite video transcoding utilities is MainConcept Reference. We set our profile to iPOD HQ NTSC and then transcode a 651MB 1080P file to an iPOD HQ 34.7MB file.
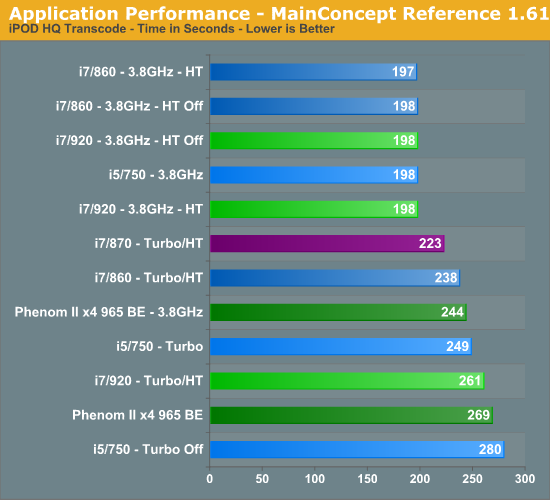
HyperThreading does not make a difference in this title with the 860/920 finishing in a dead heat again. Turbo mode for the i5/750 improves its scores by 11%. Once again, the 965 BE scales very well with an 11% increase in speed resulting in a 9% benchmark improvement. Otherwise, the 965 BE trails the 860/920/750 by 29% at 3.8GHz.
Sonar Producer 8 x64
We utilize Sonar Producer extensively at home when mixing various music tracks. This test performs a complex mix of five individual tracks into a single title. We covert these tracks into a WAV format utilizing a 192kHz sample rate along with all other options enabled. This title thrives on memory bandwidth.
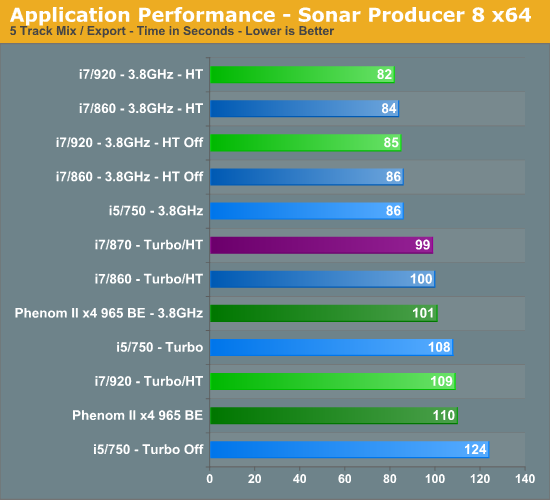
We finally see some separation between the 860 and 920 processors in this benchmark. Based on offline memory testing, we contribute this to the 920’s slightly better throughput under load conditions. The i5/750 performs 13% better with turbo enabled. The 965 BE performs 15% worse than the 750 at 3.8GHz.
Adobe Lightroom 2.4 x64
Lightroom is a quick and easy to use program for batch conversions on digital photos. We perform a standard conversion of 50 RAW images into the JPEG format.
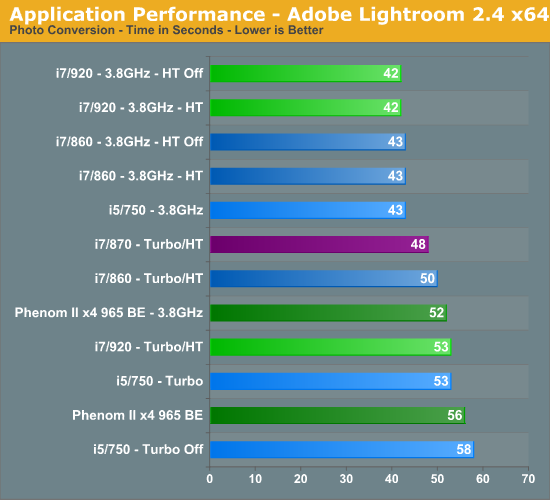
HyperThreading does not matter in this title. The 920 finishes just slightly ahead of the 860. Turbo mode makes 9% difference for the i5/750, just enough to place ahead of the 965 BE at stock speeds. Once overclocked, the 965 BE is 17% slower than the 750.
CyberLink MediaShow Espresso
We transcode a 370MB 1080AVCHD file into a HD friendly file suitable for publishing on YouTube. This program features GPU hardware accelerated decoding via ATI Stream or NVIDIA CUDA but is disabled in our test routines.
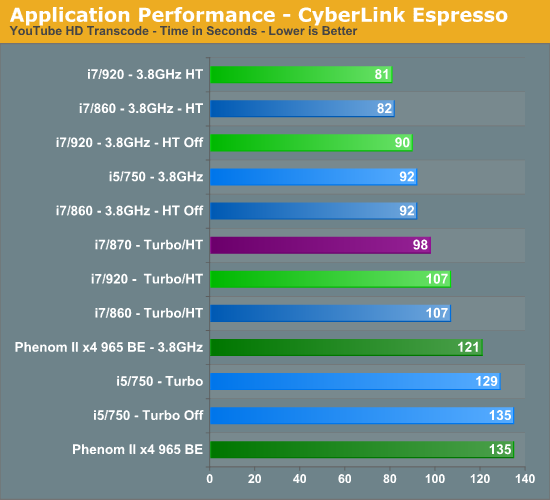
Even with a 740MHz advantage in clock speed, the 965 BE is just equal to the i5/750 with Turbo disabled in this application. Obviously, it appears this particular program behaves differently on Intel processors. Even at a 3.8GHz clock speed, the 965 BE trails the i5/750 by 24%. The 920/860 processors continue to be close, even though in this application the 920 has a slight advantage.








77 Comments
View All Comments
crimson117 - Tuesday, September 15, 2009 - link
"It is items like this that make you lose hair and delay articles. Neither of which I can afford to have happen."Thank you for making me almost choke on the scone I was eating.
Ocire - Tuesday, September 15, 2009 - link
That's some strange numbers you got there...Just an idea that popped up my mind: Could effective PCIe bandwidth be the key here?
You can do the bandwidth test that comes with nVIDIAs CUDA with the shmoo-option for pinned and unpinned memory on both platforms.
If you get higher numbers on the AMD platform, it could be that with P55 and X58 the card is in some cases interface bandwidth bound. (Which isn't that uncommon in some GPGPU applications, too)
Holly - Tuesday, September 15, 2009 - link
I was thinking about bandwidth as well, but then I realised with P55 CPU has direct lanes to first PCIe 16x slot while X58 platform runs via Northbridge... It's way too different approach to both produce same problem imho...This seems like driver issue to me. Maybe the CPU and GPU parts of the engine+drivers run asynchronous and communication in between gets suffocated (st like i7 manages to compute too fast and data have to wait for next loop to go through)...
no clue though, it's just my best guess...
TA152H - Tuesday, September 15, 2009 - link
A lot of people are getting confused by the PCIe being on the processor as opposed to the Northbridge. Because the IMC shows advantages on the processor die in terms of memory latency, and moving the floating point unit did with the 486, it's assumed moving things onto the processor die should be faster. If you look closer though, it becomes clear this just isn't so.The reason the memory controller on the processor has advantages comes down to two important considerations - it's transferring to and from the processor, and it's got finer granularity than something running at lower clock speeds.
Let's look at the second first. Let's say I'm running the processor at eight times the speed of the northbridge. The number isn't so important, and it doesn't even have to be an integer, to illustrate the point, so I'm just picking one out of the air.
Let's call clock cycle eight the one where the northbridge also gets a cycle and can work on the request from the processor, and for the sake of simplicity, the memory controller can work on it. If I get something on processor cycles one through seven, I could start the memory read on the IMC, but the slower clock speed doesn't that level of granularity, so the read, or write, request waits. This is a gross oversimplification, but you probably get the point.
Perhaps more importantly, you're transferring from memory, to the processor. It's too the actual device the memory controller is attached to. And since the memory controller is on the processor itself, there's less overhead in getting generating the request to the memory controller.
The PCIe 16 slot is a different animal. You're not generally using the processor for this, except for now. It's going from one device, typically to memory, with possible disastrous consequences for the brain-damaged Lynnfield line.
With a proper setup, there wouldn't be any real difference. I'm not sure how the Lynnfield is set up though, and I'm not sure it's a proper setup like the x58. I'll explain. If we look at the x58, the video card will transfer memory to the Northbridge, and then the Northbridge will interface to the memory. It has channels on it to do that, and it doesn't involve the processor at all, or need to.
On the Lynnfield, now you're involving the processor, for no good reason except for cost (which is a really good reason, actually). So, now the video card sends a request to the PCIe section of the processor, and the processor has to do the transfer. Now, this is the big question - just how brain-damaged is the Lynnfield? Does it actually have a seperate path to handle these transfers, or does it basically multiplex the existing narrow memory bus to handle these? It's almost certainly the latter, since I don't know how much sense it would make to only use part of the memory bus for all other transfers. Anand can hopefully answer these questions, although this site tends to never look very deep at things like this, so I'm doubtful. I guess they don't think we're interested, but I surely am.
The end result is, you could have competition for the already narrower memory bus, where the processor can get locked out of it while PCIe transfers are going on. This is consistent with some benchmarks other sites show, where the Lynnfield struggles more than it should on games.
I don't want to make this sound worse than it is though. Most video cards have a lot of memory, and the actual number of requests to memory hopefully isn't very high. Even on a Bloomfield, any request to main memory is a slow down since video memory will always be faster. Also, cards will keep getting more memory, whereas the human eye is not going to get able to discern better resolution, so presumably cards will not have to use main memory at all, in the future. And, keep in mind, processors have big L3 caches, so don't need to go out to memory all that often. So, it's not catastrophic, but you should see it, and more as you stress the CPU and GPU. Again, if you look at other websites that did some serious game stressing, you do see the Bloomfields distance themselves from their brain-damaged siblings as you stress the system more.
yacoub - Tuesday, September 15, 2009 - link
I think we'd all be interested to know the answer to this quandary, however I also think you're exaggerating a bit when you call it brain damaged and say things like "disastrous consequences". In reality what you mean is that in extreme bandwidth saturation situations like SLI it's possible it might be slower than X58, and maybe when the DX11 generation of cards come out they will actually require enough bandwidth for it to be even more noticeable in SLI comparisons. But for the vast majority of us who run a single GPU, so long as a single DX11 card doesn't fully saturate the available bus bandwidth and thus doesn't perform any less than on X58, P55 is just fine.TA152H - Wednesday, September 16, 2009 - link
I agree, when I was typing it, I meant disastrous consequences with respect to that particular instance when the processor has to multiplex. In the context of overall performance, I don't think it would be that huge. I wasn't clear about that.But, you're off with regards to the saturation. You don't have to saturate the bus, at all. You don't need two cards. That type of thinking is fallacious, in that it assumes only part of the bus is used.
In reality, ANY time the video card needs the memory bus, and the processor needs to read memory, you've got a collision, and one or the other has to wait. This would happen more often if you have more stress on the processors, or video subcomponent, but could happen even with one card, and one processor being used. It just would be much less frequent, and probably insignificant.
These are the type of compromises these web sites should be bringing up, but they simply don't. It's not just this one, but shouldn't a tech site bring up questions like this, instead of just publish benchmarks (which, as we know, are far from objective and can paint a different picture based on the parameters and benchmarks chosen).
I wouldn't expect this from PC Magazine, but from 'tech' sites? They just aren't very technical.
Gary Key - Tuesday, September 15, 2009 - link
P55 will be just fine with the DX11 cards.. whistles and grins evilly looking at the results, however, for top performance in SLI or CF, it is X58 all the way. That said, I have not been able to tell the difference between 130 FPS and 128 FPS in HAWX yet, nor between 211 FPS and 208 FPS in L4D. :)jonup - Wednesday, September 16, 2009 - link
does your comment mean that you have/have seen a HD 5870 in action?yacoub - Tuesday, September 15, 2009 - link
It appears more driver/optimization-related given that some games that are less bandwidth-intensive are showing the strange performance and others are not.yacoub - Tuesday, September 15, 2009 - link
Hey I wonder if Gary tried renaming the .exe just to see if it was a driver bug with certain game engine optimizations! :)